Quick note: If you’re building with MCP Toolbox, there’s an active community discussing implementation patterns and best practices. The Discord has the Toolbox team from Google who can answer questions directly. Check out the Discord community for real-time help.
You’re in the middle of refactoring a legacy application when a question hits: “What’s the actual distribution of user activity across our tables?” Instead of context-switching to pgAdmin, crafting SQL queries, and exporting results, you ask Claude - embedded directly in your IDE - and get a synthesized analysis with actual data in seconds.
Or you’re designing a new microservice and need to understand the existing schema relationships across three databases. Rather than opening multiple database clients and piecing together foreign key relationships manually, your AI agent queries everything in natural language and generates an accurate ERD with dependency chains.
This isn’t a demo. It’s what Google’s MCP Toolbox for Databases enables right now - and it fundamentally changes how engineering teams interact with their data infrastructure.
What is MCP Toolbox for Databases?
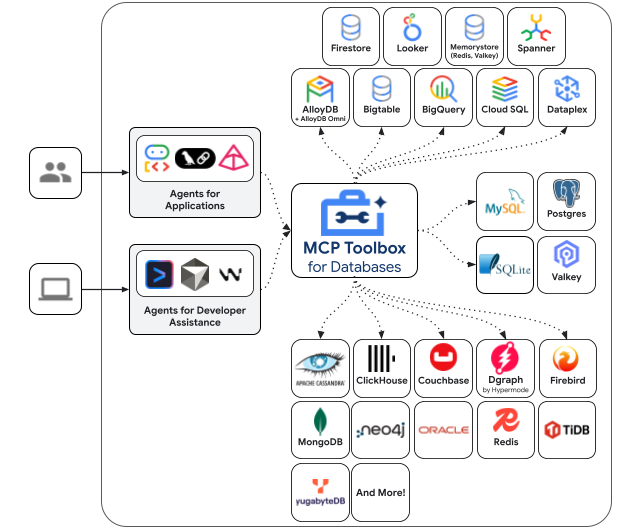
Google’s MCP Toolbox for Databases (formerly Gen AI Toolbox for Databases) is an open-source Model Context Protocol server that acts as a universal abstraction layer between AI agents and enterprise databases. Released in early 2025 and recently updated to fully support the MCP standard, it transforms how developers build AI-powered database tools.
Think of it as a production-grade middleware that handles the engineering complexity you’d otherwise implement yourself: connection pooling, OAuth2 authentication, observability instrumentation, and standardized database interactions - all exposed through a clean protocol that any MCP-compatible AI can consume.
The toolbox isn’t just another database connector. It’s a secure, observable, production-ready bridge that lets you build AI agents capable of querying AlloyDB, Cloud SQL (PostgreSQL/MySQL/SQL Server), Spanner, Bigtable, Neo4j, Dgraph, and self-managed databases - without writing boilerplate for each integration.
Here’s what matters: Google built this because they encountered the same problems you have. Every team building database-aware AI agents was reimplementing connection management, struggling with secure credential handling, and lacking visibility into what their agents were actually doing. MCP Toolbox solves those problems once, correctly, and makes it available as open source.
Understanding the Model Context Protocol (MCP) Standard
Before diving into the toolbox specifics, understanding MCP is critical - because it’s the architectural foundation that makes this entire system work.
The Model Context Protocol, introduced by Anthropic in November 2024 and formally adopted by OpenAI in March 2025, is an open standard for connecting AI systems to external data sources. Prior to MCP, every AI integration required bespoke API implementations. Want Claude to access your database? Build custom tools. Want ChatGPT to query your knowledge base? Build different custom tools. Want Cursor to interact with your CRM? You get the idea.
MCP standardizes this through a client-server architecture with JSON-RPC messaging. Servers expose three primitives:
- Prompts - Reusable prompt templates with parameters
- Resources - Content and data sources the AI can read
- Tools - Actions the AI can invoke with arguments
Clients (AI assistants like Claude, ChatGPT, Cursor, Windsurf) consume these primitives and reason about when to invoke them. The brilliance is in the abstraction: once you implement an MCP server, it works across every MCP-compatible client. Write once, run everywhere.
For databases specifically, this means:
- Natural language querying becomes a Tool the AI can invoke with SQL or semantic parameters
- Schema documentation becomes a Resource the AI can read for context
- Query templates become Prompts the AI can reuse with different parameters
Google’s MCP Toolbox implements this standard, which means any MCP client - Claude Code, Cursor, Cline, Windsurf, or custom agents built with LangChain/LlamaIndex - can immediately leverage your databases without custom integration code.
Architecture and Key Features
MCP Toolbox for Databases is designed with production workloads in mind. Here’s what’s under the hood:
1. Universal Database Connectivity
The toolbox supports an impressive range of databases out of the box:
Google Cloud Native:
- AlloyDB for PostgreSQL (including AlloyDB Omni for on-premises deployments)
- Cloud SQL for PostgreSQL, MySQL, and SQL Server
- Cloud Spanner for globally-distributed SQL
- Bigtable for high-throughput NoSQL workloads
Third-Party and Self-Managed:
- Neo4j for graph database operations (contributed by Neo4j)
- Dgraph for distributed graph queries (community contribution)
- Self-managed PostgreSQL and MySQL instances anywhere
This isn’t just support in name. Each connector is optimized for the specific database’s characteristics - AlloyDB’s ScaNN vector index for embeddings, Spanner’s global consistency model, Bigtable’s wide-column performance characteristics.
2. Enterprise-Grade Security (OAuth2/OIDC)
Authentication is where most homegrown integrations fall apart. MCP Toolbox handles this properly:
OAuth2 Integration: Instead of embedding database credentials in agent code or storing them in prompts (a security nightmare), the toolbox uses OAuth2 flows. Users authenticate once through Google Cloud’s identity system, and the toolbox manages token lifecycle - refresh, expiration, revocation.
OpenID Connect (OIDC): For enterprise deployments with existing identity providers, OIDC integration means agents authenticate against your Okta, Azure AD, or Auth0 setup. This preserves your existing access control policies and audit trails.
IAM Integration: For Google Cloud databases, the toolbox leverages Cloud IAM directly. Your database permissions, roles, and service account configurations apply automatically. No separate credential management needed.
Here’s what this looks like in practice:
# tools.yaml configuration
databases:
production_db:
type: alloydb
instance: projects/my-project/instances/prod-alloydb
database: users
auth:
type: oauth2
scopes:
- https://www.googleapis.com/auth/cloud-platformThe OAuth flow happens once during setup. After that, agents query databases securely without seeing credentials.
3. Built-in Observability with OpenTelemetry
Production AI systems need visibility. What queries are agents running? How often? What’s failing? MCP Toolbox ships with OpenTelemetry instrumentation out of the box.
Automatic Metrics:
- Query execution time (p50, p99, max)
- Connection pool utilization
- Query success/failure rates
- Token consumption per query (for cost tracking)
Distributed Tracing: Every agent action generates a trace that flows from the AI’s decision to invoke a tool, through the MCP protocol, into the database query, and back. When debugging why an agent gave the wrong answer, you can see exactly what queries it ran and what data it received.
Integration with Observability Platforms: The OpenTelemetry data exports to any compatible backend - Google Cloud Operations, Datadog, New Relic, Honeycomb, or platforms like Agnost AI that specialize in AI agent observability. This means you can monitor agent behavior alongside your existing infrastructure metrics.
For engineering teams evaluating this for production, observability isn’t optional - it’s the difference between “it works on my machine” and “we can debug production issues.” The toolbox handles this complexity so you don’t have to instrument it yourself.
4. Connection Pooling and Performance Optimization
Naive database access from AI agents creates connection storms. Every agent invocation opens a connection, runs a query, closes the connection. At scale, this kills database performance.
MCP Toolbox implements intelligent connection pooling with:
- Per-database pool configuration: Different databases have different optimal pool sizes. AlloyDB can handle more concurrent connections than a self-managed PostgreSQL instance.
- Automatic connection lifecycle management: Idle connections are recycled, failed connections are retried with exponential backoff, and connection limits prevent overwhelming the database.
- Query result caching: For frequently accessed schema information or reference data, the toolbox caches results in-memory to reduce database load.
This matters in multi-agent scenarios where dozens of agents might be querying simultaneously. The toolbox ensures that scales without degrading database performance.
Supported Frameworks and SDKs
Building AI agents requires orchestration frameworks. MCP Toolbox integrates with the major players:
LangChain Integration
LangChain remains the most popular framework for building LLM applications. The MCP Toolbox provides a native LangChain integration through the genai-toolbox-langchain-python SDK.
from langchain_google_genai import ChatGoogleGenerativeAI
from genai_toolbox_langchain import GenAIToolboxTools
# Initialize database tools from MCP Toolbox
db_tools = GenAIToolboxTools.from_config("tools.yaml")
# Create agent with database access
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-exp")
agent = create_react_agent(llm, db_tools.get_tools())
# Agent can now query databases naturally
response = agent.invoke({
"input": "What's the distribution of user signups by country in the last 30 days?"
})The SDK handles tool registration, parameter validation, and result formatting automatically. Your agent gets clean Python functions to invoke; the toolbox handles the MCP protocol and database interaction.
LlamaIndex Integration
For RAG (Retrieval-Augmented Generation) pipelines that need database grounding, the genai-toolbox-llamaindex-python SDK integrates MCP Toolbox as a LlamaIndex tool source:
from llama_index.core.agent import ReActAgent
from genai_toolbox_llamaindex import GenAIToolboxToolSpec
# Load database tools
toolbox_spec = GenAIToolboxToolSpec.from_config("tools.yaml")
# Agent can query databases as part of RAG pipeline
agent = ReActAgent.from_tools(
toolbox_spec.to_tool_list(),
llm=llm,
verbose=True
)This is powerful for scenarios like “summarize customer feedback from our support tickets database and cross-reference with product usage data” - the agent queries structured data alongside vector stores.
Genkit Support
Google’s Genkit framework (the successor to Firebase’s gen AI experiments) has first-class MCP Toolbox support across JavaScript, Go, and Python SDKs.
The integration is particularly clean in TypeScript:
import { genkit } from 'genkit';
import { mcp } from '@toolbox-sdk/genkit';
const ai = genkit({
plugins: [
mcp({
serverPath: './mcp-toolbox',
configPath: './tools.yaml'
})
]
});
// Define flow with database access
const analyzeUsers = ai.defineFlow(
{ name: 'analyzeUsers' },
async (input: { timeframe: string }) => {
const result = await ai.generate({
prompt: `Analyze user activity patterns for ${input.timeframe}`,
tools: ['query_database', 'aggregate_metrics']
});
return result.text();
}
);Genkit’s deployment model (Cloud Run, Cloud Functions) pairs naturally with MCP Toolbox’s Cloud SQL and AlloyDB support.
Direct SDKs (Python/JavaScript/TypeScript/Go)
For teams building custom agent frameworks or integrating into existing systems, Google provides language-specific SDKs without framework dependencies:
- Python:
mcp-toolbox-sdk-python - JavaScript/TypeScript:
mcp-toolbox-sdk-js - Go:
mcp-toolbox-sdk-go
These SDKs expose the MCP protocol directly, giving you full control over tool invocation, error handling, and response parsing.
Practical Implementation: Agent Development Kit (ADK)
Google’s Agent Development Kit (ADK) - released in early 2025 as an open-source Python framework - is purpose-built for multi-agent systems and integrates seamlessly with MCP Toolbox.
ADK’s killer feature for database-aware agents is state management with LangGraph integration. Here’s why this matters:
Most AI agents are stateless - every interaction starts from scratch. For database operations, this is limiting. You want agents that remember:
- Previous query results to avoid re-fetching the same data
- Schema information discovered during the session
- User preferences for output formatting
- Complex multi-step operations in progress
ADK implements this through LangGraph’s checkpointing system, which persists agent state across invocations. Combined with MCP Toolbox, you can build agents that:
- Query a database to understand available tables
- Ask clarifying questions to the user based on discovered schema
- Execute the final query with context from previous steps
- Format results based on user’s preferred output from earlier in the conversation
Here’s a simplified architecture:
from adk import Agent, State
from genai_toolbox_langchain import GenAIToolboxTools
# Define agent state with database context
class DBAgentState(State):
schema_cache: dict = {}
query_history: list = []
user_preferences: dict = {}
# Create stateful agent
agent = Agent(
name="database_analyst",
state_type=DBAgentState,
tools=GenAIToolboxTools.from_config("tools.yaml").get_tools(),
checkpointer="postgres://state_db" # LangGraph checkpoint storage
)
# Agent maintains state across conversations
session_id = "user_123_session"
agent.invoke(
"What tables are available?",
session_id=session_id
)
# State stores schema information
agent.invoke(
"Show me users from the customers table",
session_id=session_id
)
# Agent remembers 'customers' exists from previous queryFor production systems handling multiple concurrent users, this state persistence is essential. The agent doesn’t just answer queries - it learns about your database during the session and gets smarter with each interaction.
Real-World Example: Travel Agent Use Case
Google provides an excellent codelab demonstrating MCP Toolbox in action: building a travel agent that helps users find hotels.
The implementation showcases practical patterns engineering teams will reuse:
Architecture Overview
Database Layer: Cloud SQL for PostgreSQL with a hotels database containing:
- Hotel listings (name, location, amenities, ratings)
- Room availability and pricing
- Guest reviews and ratings
MCP Toolbox Configuration: Exposes three database tools:
search_hotels- Natural language search across hotel dataget_hotel_details- Retrieve full information for a specific hotelcheck_availability- Query room availability for date ranges
Agent Layer: Built with ADK, the agent orchestrates multiple tool calls:
- Parse user intent (“Find pet-friendly hotels in Seattle under $200/night”)
- Query database via MCP tools
- Synthesize results into natural language
- Handle follow-up questions with conversation context
Key Implementation Details
The codelab demonstrates tools.yaml configuration:
tools:
- name: search_hotels
description: "Search hotels by location, price, amenities, and ratings"
database:
type: cloudsql
instance: travel-agent:us-central1:hotels-db
database: hotels
query_template: |
SELECT name, location, price_per_night, rating, amenities
FROM hotels
WHERE location ILIKE $location
AND price_per_night <= $max_price
AND rating >= $min_rating
AND amenities @> $required_amenities
ORDER BY rating DESC, price_per_night ASC
LIMIT 10
parameters:
- name: location
type: string
description: "City or region to search"
- name: max_price
type: number
description: "Maximum price per night in USD"
- name: min_rating
type: number
description: "Minimum hotel rating (1-5 stars)"
- name: required_amenities
type: array
description: "Required amenities (pool, gym, wifi, etc.)"The agent then uses this tool naturally:
User: "I need a hotel in Seattle next weekend, pet-friendly, under $200."
Agent: [Invokes search_hotels with parameters:
location: "Seattle",
max_price: 200,
required_amenities: ["pet-friendly"]
]
Database returns 7 hotels matching criteria.
Agent: "I found 7 pet-friendly hotels in Seattle under $200/night.
Here are the top-rated options:
1. Harbor Inn (4.5 stars) - $185/night
Amenities: Pet-friendly, WiFi, Parking, Waterfront
2. Green Lake Lodge (4.3 stars) - $165/night
Amenities: Pet-friendly, WiFi, Kitchen, Garden
Would you like more details on any of these?"Testing and Deployment
The codelab covers both local development and production deployment:
Local Testing:
- Run MCP Toolbox binary locally with
genai-toolbox serve --config tools.yaml - Connect ADK agent to localhost MCP server
- Test tool invocations in isolation before deploying
Cloud Run Deployment:
- Package agent and MCP Toolbox as container
- Deploy to Cloud Run with Cloud SQL connection
- Configure IAM for database access
- Enable Cloud Logging for observability
The deployment pattern is production-ready: the agent scales automatically with Cloud Run, the MCP Toolbox handles connection pooling, and all database queries flow through properly authenticated connections.
Production Considerations for Engineering Teams
If you’re evaluating MCP Toolbox for production use, here are the critical factors:
1. Cost and Performance Implications
Database Query Costs: AI agents can be query-heavy. A single natural language request might trigger 5-10 database queries as the agent explores schema, runs actual queries, and validates results. Monitor query volume carefully, especially for Cloud Spanner (which charges per query) and Bigtable (which charges per operation).
Connection Pool Tuning: The default connection pool settings (10 min, 50 max connections per database) work for most scenarios, but high-traffic agents need tuning. Monitor connection wait times and pool exhaustion metrics.
LLM Token Costs: When agents query large result sets, token consumption can spike. The toolbox doesn’t limit result size by default - implement application-level limits in your prompts (“return maximum 100 rows”).
Observability Overhead: OpenTelemetry instrumentation adds latency (typically 5-10ms per query). For ultra-low-latency requirements, you might disable detailed tracing in production and enable it only for debugging.
2. Security and Compliance
Data Access Auditing: The OpenTelemetry traces include the actual queries agents execute. Ensure your observability backend has appropriate access controls - these traces contain potentially sensitive query patterns and data.
PII and Sensitive Data: Agents might inadvertently query and process personally identifiable information (PII). Implement application-level controls to filter sensitive columns or limit query scope. The toolbox doesn’t provide data masking out of the box.
Credential Rotation: OAuth2 tokens expire and require refresh. The toolbox handles this automatically, but ensure your Cloud IAM policies allow token refresh. Failed refreshes will cause agent queries to fail silently.
3. Monitoring and Observability
For production deployments, integrate MCP Toolbox metrics with your existing monitoring:
Critical Metrics to Track:
- Query success rate (target: >99%)
- p99 query latency (varies by database, but >1s is slow)
- Connection pool utilization (>80% indicates scaling issues)
- OAuth token refresh failures (should be near zero)
- Agent tool invocation rate (for capacity planning)
Integration with Observability Platforms: Export OpenTelemetry data to any compatible observability backend. For AI-specific insights, tools that understand agent-specific metrics like tool invocation patterns, reasoning traces, and conversation flows provide better debugging context than generic application monitoring.
Distributed Tracing: When debugging unexpected agent behavior, tracing is invaluable. A trace shows:
- Which user prompt triggered the agent
- How the LLM reasoned about which tools to invoke
- What parameters it passed to MCP Toolbox
- The actual SQL query executed
- Query results returned
- How the agent synthesized the final response
This end-to-end visibility is essential for production AI systems.
4. Scaling Patterns
Horizontal Scaling: MCP Toolbox is stateless (beyond connection pooling). Deploy multiple instances behind a load balancer for high-traffic scenarios. Each instance maintains its own connection pool.
Regional Deployment: For globally-distributed applications, deploy MCP Toolbox instances in the same region as your databases to minimize latency. Cloud Spanner’s multi-region support pairs well with this pattern.
Multi-Tenant Considerations: If building a SaaS application where multiple customers’ agents query separate databases, configure one toolbox instance per tenant with isolated connection pools and OAuth credentials. Don’t share connection pools across tenants.
Getting Started: Practical Next Steps
Ready to implement this in your environment? Here’s the recommended path:
1. Star the Repository
Show support for the project and stay updated on releases: github.com/googleapis/genai-toolbox
The repository includes example configurations, integration tests, and contribution guidelines if you want to add support for additional databases.
2. Run the Travel Agent Codelab
Before building your own agent, work through Google’s Travel Agent codelab. It provides a complete working example you can modify for your use case.
The codelab takes about 90 minutes and covers setup, configuration, local testing, and Cloud Run deployment.
3. Start with a Read-Only Use Case
Your first production implementation should be read-only queries against a non-critical database. This limits blast radius while you learn the system’s behavior.
Good starter projects:
- Schema documentation agent (queries information_schema)
- Database health dashboard (queries system metrics)
- Natural language reporting (queries business analytics tables)
Avoid starting with write operations (INSERT/UPDATE/DELETE) until you’re confident in the agent’s behavior and have proper safeguards.
4. Implement Observability First
Before deploying to production, connect OpenTelemetry export to your observability platform (Google Cloud Operations, Datadog, New Relic, Agnost AI, or other AI-focused monitoring tools). You want visibility into agent behavior from day one.
Set up alerts for:
- Query failure rate exceeding 1%
- p99 latency exceeding your SLA
- Connection pool exhaustion
- OAuth token refresh failures
5. Join the Community
The Toolbox team from Google is actively present in the community channels, so if you hit blockers, have architectural questions, or want feedback on your approach, there’s always someone available to help:
- Discord: The community Discord is where the Toolbox team hangs out alongside engineers sharing patterns, debugging issues, and showing what they’ve built. Direct access to the builders is a massive advantage.
- GitHub Discussions: The googleapis/genai-toolbox repository has active discussions on features, bugs, and best practices where the team responds regularly
- Google Cloud Community: Broader discussions on MCP Toolbox in production environments
The Bottom Line
Google’s MCP Toolbox for Databases solves a real engineering problem: building production-grade AI agents that interact with databases is complex. Authentication is hard. Connection management is hard. Observability is hard. Building this yourself means weeks of engineering effort and ongoing maintenance.
MCP Toolbox handles the complexity correctly, once, and makes it available as open source. The Model Context Protocol standard ensures your investment works across Claude, ChatGPT, Cursor, and any future MCP-compatible AI.
For engineering teams, this isn’t just a tool - it’s a force multiplier. Your developers get natural language access to databases from their IDE. Your AI agents get secure, observable, performant database access without custom integration code. Your operations team gets OpenTelemetry instrumentation for debugging and capacity planning.
The technology is production-ready today. The integrations exist. The documentation is solid. If you’re building AI agents that need database access, this is the foundation to start from - not build yourself.
Key Takeaway: Google’s MCP Toolbox for Databases eliminates the undifferentiated heavy lifting of building database-aware AI agents, providing production-grade security, observability, and performance out of the box through the Model Context Protocol standard.
SEO Metadata
Meta Description: Technical guide to Google’s MCP Toolbox for Databases. Learn about Model Context Protocol integration, database security with OAuth2, OpenTelemetry observability, and building production AI agents with AlloyDB, Cloud SQL, and Spanner.
Target Keywords:
- Short-tail: MCP Toolbox, Google Cloud databases, AI database integration
- Long-tail: How to integrate AI agents with databases, Model Context Protocol for databases, AlloyDB AI agent development, LangChain database tools Google Cloud, OpenTelemetry AI agent monitoring
Suggested Internal Links:
- MCP Analytics Guide
- Testing MCP Servers Complete Guide
- Top 10 MCP Servers for Coding
Content Stats: ~2400 words, 12-15 minute read