MCP (Model Context Protocol) is becoming the standard way for LLMs to talk to external systems. Claude does it. ChatGPT will do it. Everyone’s building MCP servers.
But here’s the thing: most MCP servers feel like they were designed for REST clients, not reasoning engines.
The difference? Models don’t read documentation. They infer intent from tool descriptions, chain multiple calls together, and optimize for token efficiency. If your MCP server doesn’t account for that, you’re making the model work harder than it should.
Here’s what actually matters when building one. We’ll use a GitHub MCP server as our running example.

Think in Workflows, Not Endpoints
Stop mirroring your API structure.
If you’re building a GitHub MCP server and exposing something like:
GET /repos/{owner}/{repo}
POST /repos/{owner}/{repo}/issues
GET /repos/{owner}/{repo}/commitsThe model doesn’t care about your REST conventions. It wants:
get_repository(owner, repo)
# Fetches repository details including stars, forks, open issues, and default branch
create_issue(owner, repo, title, body)
# Creates a new issue in the specified repository
list_recent_commits(owner, repo, branch)
# Returns the last 10 commits from a branch with author and messageGroup operations by what someone is trying to do, not how GitHub’s API happens to be structured. Fewer hops, fewer mistakes.
Return IDs and Everything Else the Model Might Need Next
Don’t make the model ask twice for information you already have.
When you return a list of repositories, include everything the model might need for follow-up actions:
[
{
"name": "mcp-server-github",
"full_name": "username/mcp-server-github",
"owner": "username",
"default_branch": "main",
"open_issues": 3,
"url": "https://github.com/username/mcp-server-github"
}
]Now the model can immediately call get_repository("username", "mcp-server-github") or list_issues("username", "mcp-server-github") without fumbling around.
Same goes for issue responses. Include the issue number, state, assignee, and labels. If there’s a chance it’ll be useful in the next step, just include it.
This is how you get smooth multi-turn reasoning instead of clunky back-and-forth.
Your Docstrings Are the Manual
The model reads your tool descriptions the way you’d skim API docs before using a new library.
Write them like you’re explaining to a junior dev:
Bad:
def get_repo(owner, repo):
"""Gets a repository"""Good:
def get_repository(owner: str, repo: str):
"""
Fetches detailed information about a GitHub repository.
Args:
owner: Repository owner's username (e.g., "torvalds")
repo: Repository name (e.g., "linux")
Returns:
Repository details including stars, forks, open issues count,
default branch, description, and primary language.
Common errors:
- 404: Repository not found or private
- 403: Rate limit exceeded
"""Skip the corporate speak. Be specific. If a field is optional, say so. If there’s a common mistake, warn about it.
Good docstrings mean better tool selection and fewer retries.
Mix Tools and Prompts
Not everything needs to be a function call.
Most MCP clients support both tools and prompts. Use tools for actions (create issues, fetch code). Use prompts for reasoning (analyze commit history, suggest fixes).
For example:
- Tool:
get_pull_request(owner, repo, number)- Fetches PR details - Prompt: “Analyze this PR diff and suggest potential issues”
Sometimes the model just needs to think out loud before making a call. Let it.
Watch Your Token Budget
Every schema you expose costs tokens. Every verbose response adds up.
When returning commit history, don’t dump the entire diff if the model just needs commit messages:
Bloated response (1000+ tokens):
{
"sha": "a1b2c3d",
"commit": {
"author": {
"name": "Jane Dev",
"email": "[email protected]",
"date": "2025-10-12T10:30:00Z"
},
"committer": { /* ... */ },
"message": "Fix authentication bug",
"tree": { /* ... */ },
"url": "...",
"comment_count": 0,
"verification": { /* ... */ }
},
"stats": { /* ... */ },
"files": [ /* full diff for each file */ ]
}Optimized response (50 tokens):
{
"sha": "a1b2c3d",
"author": "Jane Dev",
"message": "Fix authentication bug",
"date": "2025-10-12"
}Audit your payloads:
- Drop fields the model won’t use
- Shorten enum names (
openvsISSUE_STATE_OPEN) - Keep error messages clear but brief
Smaller responses mean faster reasoning and lower costs. It’s not premature optimization. It’s respecting the constraints you’re working within.
Measure What’s Actually Happening
You can’t fix what you don’t track.
For your GitHub MCP server, log:
- Which tools get called (
get_repositoryvssearch_code) - How often they fail (rate limits? auth errors?)
- Response times (is
search_codeslow?) - Token usage per operation
Once you see the data, patterns emerge. Maybe list_repositories is getting hammered because you’re not including enough context in the first response. Maybe create_issue keeps failing because your error messages don’t explain what’s wrong.
Fix those, and your whole system gets smarter.
If you want a ready-made solution, we built Agnost AI specifically for this. It tracks your MCP server’s performance, usage patterns, and bottlenecks so you’re not flying blind.
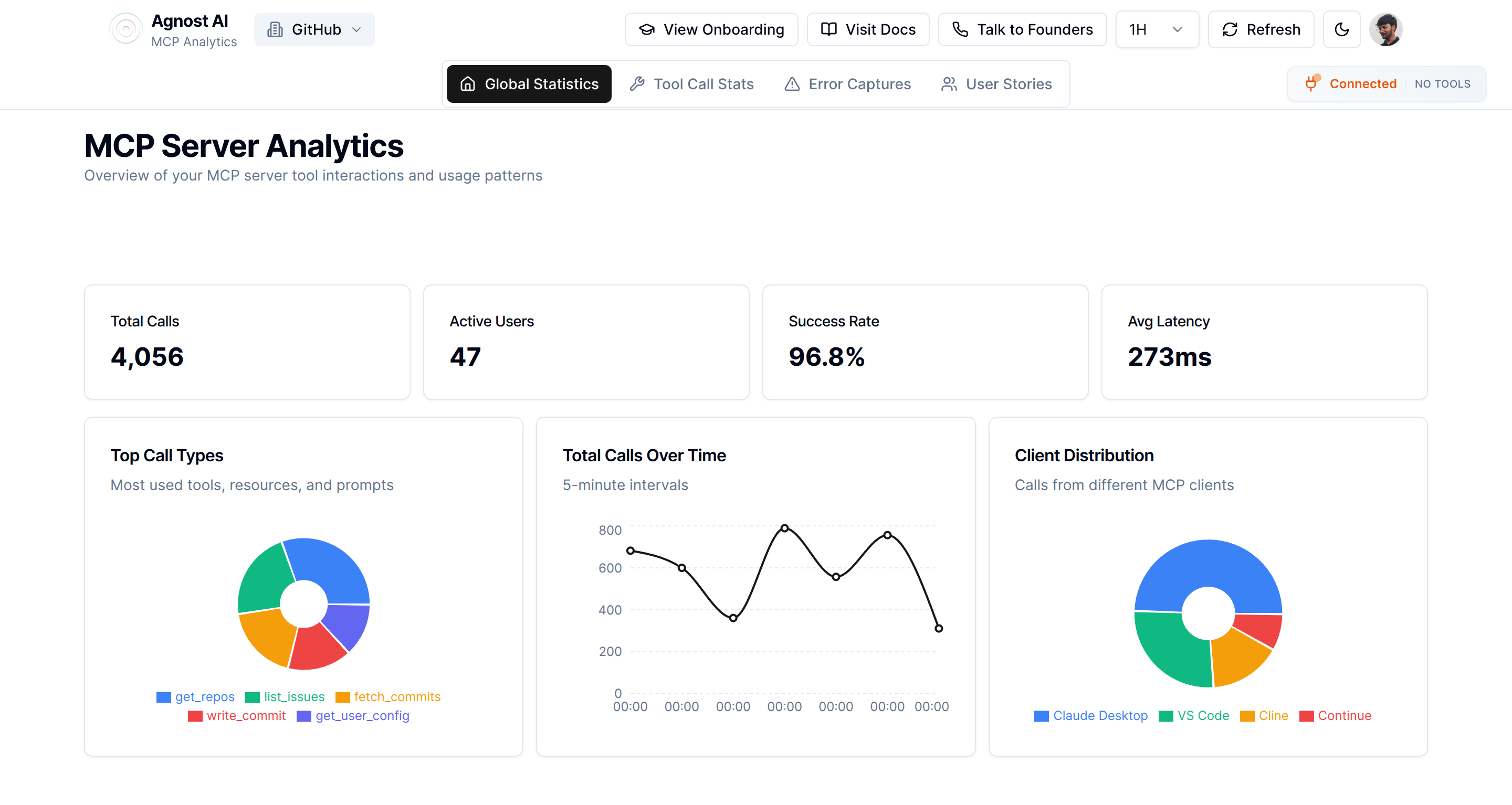
Get a Second Opinion
If you’ve already shipped an MCP server and it works but doesn’t feel great, we can help.
We’ve reviewed dozens of early MCP implementations and helped teams make them faster, easier to use, and more model-friendly.
Call us and we’ll take a look.
Bottom Line
The best MCP servers don’t just work. They anticipate how the model will use them.
They’re context-aware. They chain well. They don’t waste tokens.
If you’re building one, design it like you’re teaching a smart but impatient colleague. Clear, concise, and ready for follow-up questions.
Whether you’re building a GitHub integration, a Slack bot, or a database connector, the same principles apply: think in workflows, return rich context, write clear descriptions, and measure everything.
Connect with MCP Builders
Building great MCP servers is easier when you’re learning from others. Join our Discord community to share your implementations, ask questions, discuss best practices, and stay updated on new MCP servers and tools.